
 RSS
RSS

相关性 截至 11 年 2020 月 XNUMX 日的冠状病毒死亡率 在州一级全面薄弱:
肥胖率 — (.13)
中位年龄——09
克林顿 2016 年的投票份额 — (.04)
人口密度——13
白人人口百分比 - (.18)
黑人人口百分比 — .20
亚洲人口百分比 - .13
西班牙裔人口 % — .11
还有什么其他的东西可以作为一个潜在的有意义的关联,或者是在查看州级的不精确?
五州——阿肯色州、爱荷华州、内布拉斯加州、北达科他州和南达科他州——仍未发布就地避难令。 他们的冠状病毒死亡率目前为百万分之九。 在全国范围内,冠状病毒死亡率为百万分之 9。 这些州受到的打击几乎没有全国其他地区那么严重,至少现在还没有。
尽管我们在几周前预测全国的死亡人数将低于 100,000 时受到了一些嘲笑,但现在看来这就是赌注的方式——至少在瘟疫的第一波中是这样。 这是个好消息,对每个人来说都是一个可喜的解脱。
仍然悬在我们头上的大问题是真正的感染率,而不仅仅是症状率。 假设得到这个答案的问题涉及扩大管理数千万或数亿次测试的能力。
好的,但与此同时,像盖洛普这样的组织能否与几个测试生产商合作,对具有全国代表性的几千人样本进行测试? 我们不是对人们的政治观点进行民意调查,而是对他们的冠状病毒抗体或是否缺乏进行调查。
如果我们最终发现渗透率远高于最初的猜测——因此死亡率要低得多——我们可以结束对大多数人来说就地避难、社会疏远和其他经济灾难性策略。 相反,这些限制性措施的责任可以放在高风险人群身上,直到检测能力变得无处不在,为他们保留的检测资源有限。
如果事实证明是这样的话,我们真的会因为上个月没有意识到这一点而自责,因为它不仅可以用我们今天的一小部分测试能力来完成,甚至可以用我们的与几周前相比,容量更加有限。




与任何疾病一样,一般健康状况将是预后的最大因素。
肥胖、药物滥用和潜在的健康状况是这里的因素。
当然,酒精似乎对 Covid-19 有益。
我猜,由于饮食不良、肥胖率和药物问题,少数族裔受到了沉重打击。
我希望看到与年度流感类似的相关性。
然后我们就会知道我们是否只是在关注正常的疾病问题或与该病毒相关的特定问题。
回复:@res
想到其他任何可能有意义的关联
教育年限?
“还有什么其他可能是有意义的关联,或者说是在州层面上的不精确?”
该州的北部或南部有多远呢?
同意,纬度是传播的最初大问题之一,以及环境温度和湿度
平均露点怎么样。 这是各州的数据。
https://www.forbes.com/sites/brianbrettschneider/2018/08/23/oh-the-humidity-why-is-alaska-the-most-humid-state/
查看 XNUMX 月、XNUMX 月和 XNUMX 月的平均露点可能会更好,但该数据更难收集。
或者温度。 这是平均气温和冬季平均气温。
https://www.currentresults.com/Weather/US/average-annual-state-temperatures.php
https://www.currentresults.com/Weather/US/average-state-temperatures-in-winter.php
或降水。
https://www.currentresults.com/Weather/US/average-annual-state-precipitation.php
同样,季节性可能会更好。
另一方面,人格特质如何? 这篇论文的最后一页有一个按州划分的 5 大表格。 将这些用于其他目的也可能很有趣。
https://www.apa.org/news/press/releases/2013/10/regions-personalities
https://www.apa.org/pubs/journals/releases/psp-a0034434.pdf
作为二进制变量的就地避难所顺序和初始/最强顺序的日期似乎可能是有用的变量。
PS您(AE)是否尝试过任何多元回归? 看到种族(4 个类别变量)、肥胖、密度、露点和外向性之类的东西会很有趣。 然后进行一些分析以了解它们如何协同工作(ANOVA?)。
PPS 同意状态相当不精确。 好像大城市会好点。 特别是因为现在他们似乎正在推动传播。
回复:@ res,@ Audacious Epigone
人口密度应该是一个因素。 在其他条件相同的情况下,预计集中在一个城市的一百万人口的渗透率要比分布在广大地区的相同人口的渗透率更高。
真正难以做到的事情之一是住院、严重程度和死亡率数据中绝对明显的年龄组划分。
从 'Infected' 到 ' 的额外转换概率被感染,症状严重到足以产生 T是',其中一些子集需要 H精神化,其中一些 D即。似乎各个年龄组(例如非常年轻)的感染率(非常)大致保持不变 - 尽管必须牢记要计入 I 你必须经过测试,这在美国是一个非常有偏见的样本。
这就像在 SEIR 模型中还有另外两个隔间:
不过,这并不意味着 Pr(I|E) 在各个年龄段都是恒定的:相对更强壮的 20-29 岁的人在给定的暴露水平下感染的机会可能较低。
20-29 岁人群的超额感染率(在澳大利亚数据中占其人口份额的 150%)可能表明这些人的社交互动最多——他们的大部分社交互动将在群体内进行。
相反,平均 70 岁以上的病人——迄今为止,在死亡人数中所占比例最高——与 covid19 的社会接触范围要窄得多(并且变化较少):在正常的事件过程中,它是家庭或疗养院的工作人员 -如果一名工作人员无症状,他们可能会感染疗养院的数十名囚犯。
对不同年龄组的转换概率进行建模是一项挑战,因为每个年龄组的联系人的年龄分布将不同 - 70 多个年龄组中的 I、T、H 和 D 中的数字可能来自从 20-29yo 的接触中暴露(反之亦然)。
该州的北部或南部有多远呢?
回复:@Oo-ee-oo-ah-ah-ting-tang-walla-walla-bing-bang,@res
同意,纬度是传播的最初大问题之一,以及环境温度和湿度
因此,说“拉丁语受灾最严重”有点牵强。 为什么我不惊讶?
整个州的人口密度对于像华盛顿这样的州来说意义不大。 这是一个很大的地方,东部,什么,三分之二? 很空。 但西雅图是一个大而拥挤的城市。
我会看看一个州最大城市的人口密度。
出于好奇,测试它们有什么用?
坦率地说:限制对出现症状的人进行检测是一种花招,只不过是为了流行病学的目的而将几类政治上有用但在其他方面无用的信息加起来而已。 认真研究人员的第一步应该正是了解这种东西在普通人群中的毒性有多大,然后才开始提出更极端的缓解措施。 多年来,诸如洗手、减少握手、打喷嚏等缓解措施已张贴在医生办公室、公司公告板、商店等处。
事实上,报告的总数仍然相对微不足道。 到目前为止,这只不过是一个非常糟糕的流感季节。
但这已经被激化为一种用来排在某些政党口袋里的狂热,而且,从 MSM 问题和八角盒圆桌讨论来看,似乎是为了推翻坏橘子人并推进一个无法以更空灵的方式推进的国家主义议程像气候变化这样的原因,它只会在十几年内杀死我们,而不是在接下来的 18 天内。
肥胖、药物滥用和潜在的健康状况是这里的因素。
当然,酒精似乎对 Covid-19 有益。
我猜,由于饮食不良、肥胖率和药物问题,少数族裔受到了沉重打击。
回复:@Justvisiting
我希望看到与年度流感类似的相关性。
然后我们就会知道我们是否只是在关注正常的疾病问题或与该病毒相关的特定问题。
我在这里回复的 utu 的评论:
https://www.unz.com/isteve/new-york-vs-california/#comment-3831677
有 CDC 数据的链接。 我链接了我的评论,因为我谈论的是年龄调整与原始死亡率。 这很重要。 我认为选择使用哪个取决于您要完成的工作。
尚未发布就地庇护令的五个州可能需要重新考虑。 CDC 的一份新报告称,该病毒可以传播 13 英尺:
https://nypost.com/2020/04/12/the-coronavirus-can-travel-at-least-13-feet-new-study-shows/
其他州几乎关闭了一切,但上个月,每个人都在杂货店排队等候,彼此相距六英尺,这样他们就可以得到食物而不会饿死。 这种类型的关闭可能不像以前想象的那么有效,因此我们可能已经破坏了经济,在阻止疾病传播方面取得的成果比我们想象的要少。
马克,13 英尺? 不是27? 不是 14 或 12 英尺? 6英尺安全吗? 里面还是外面? 有风还是无风? 是否像篝火冒出的烟雾一样悬挂在空气中(静止的空气?完全静止??)?
我打电话给BS。 它是各种流感。 杀死一些人。 BFD。 可能会杀了我,我想。 每个人都死于某种东西。 我从没想过管理这个国家的白痴会关闭它,因为如果我死了,他们就给了它,我现在不这么认为。 这是一个骗局,被用来压制人们并实现接管,否则对于工作它的精神病患者来说,这将不是那么容易。
该州的北部或南部有多远呢?
回复:@Oo-ee-oo-ah-ah-ting-tang-walla-walla-bing-bang,@res
平均露点怎么样。 这是各州的数据。
https://www.forbes.com/sites/brianbrettschneider/2018/08/23/oh-the-humidity-why-is-alaska-the-most-humid-state/
查看 XNUMX 月、XNUMX 月和 XNUMX 月的平均露点可能会更好,但该数据更难收集。
或者温度。 这是平均气温和冬季平均气温。
https://www.currentresults.com/Weather/US/average-annual-state-temperatures.php
https://www.currentresults.com/Weather/US/average-state-temperatures-in-winter.php
或降水。
https://www.currentresults.com/Weather/US/average-annual-state-precipitation.php
同样,季节性可能会更好。
另一方面,人格特质如何? 这篇论文的最后一页有一个按州划分的 5 大表格。 将这些用于其他目的也可能很有趣。
https://www.apa.org/news/press/releases/2013/10/regions-personalities
https://www.apa.org/pubs/journals/releases/psp-a0034434.pdf
作为二进制变量的就地避难所顺序和初始/最强顺序的日期似乎可能是有用的变量。
PS您(AE)是否尝试过任何多元回归? 看到种族(4 个类别变量)、肥胖、密度、露点和外向性之类的东西会很有趣。 然后进行一些分析以了解它们如何协同工作(ANOVA?)。
PPS 同意状态相当不精确。 好像大城市会好点。 特别是因为现在他们似乎正在推动传播。
由于露点相对于特定湿度是非线性的(并且 R0 相对于特定湿度是非线性的,我认为这会放大问题),因此尝试对露点进行一些变换可能是有意义的。 上个月此评论中的一些相关图形。
https://www.unz.com/anepigone/covid-19s-hard-fail/#comment-3764901
我没有。 我用于多变量分析的工具包目前不起作用。 如果尘埃落定时还没有解决,我会再买一个,但我会等到那时再发布其他任何东西。 感觉这可能比在这一点上澄清数字更令人困惑,因为数字像它们一样跳来跳去。
我会看看一个州最大城市的人口密度。
回复:@res
好主意
我希望看到与年度流感类似的相关性。
然后我们就会知道我们是否只是在关注正常的疾病问题或与该病毒相关的特定问题。
回复:@res
我在这里回复的 utu 的评论:
https://www.unz.com/isteve/new-york-vs-california/#comment-3831677
有 CDC 数据的链接。 我链接了我的评论,因为我谈论的是年龄调整与原始死亡率。 这很重要。 我认为选择使用哪个取决于您要完成的工作。
大胆的 Epigone,我认为查看纬度会非常有趣,因为它显示了这种病毒在多大程度上是季节性的。
我制作了下表,它给出了每个州最大城市的纬度。 然后为了更好地显示范围,我从纬度中减去了 29。 为了更好地了解相关性,您可能需要删除远在其他范围之外的阿拉斯加和夏威夷。
对于纬度变化较大的国家,这些相关性更为明显。
州/最大城市纬度最大城市纬度-29
阿拉巴马州:伯明翰 33.5186 4.5186
阿拉斯加:安克雷奇 61.2181 32.2181
亚利桑那州:凤凰城 33.4484 4.4484
阿肯色州:小石城 34.7465 5.7465
加利福尼亚州:洛杉矶 34.0522 5.0522
科罗拉多州:丹佛 39.7392 10.7392
康涅狄格州:布里奇波特 41.1792 12.1792
特拉华州:威尔明顿 39.7447 10.7447
佛罗里达州:杰克逊维尔 30.3322 1.3322
乔治亚州:亚特兰大 33.749 4.749
夏威夷:檀香山 21.3069 -7.6931
爱达荷州:博伊西 43.615 14.615
伊利诺伊州:芝加哥 41.8781 12.8781
印第安纳州:印第安纳波利斯 39.7684 10.7684
爱荷华州:得梅因 41.5868 12.5868
堪萨斯州:威奇托 37.6872 8.6872
肯塔基州:路易斯维尔 38.2527 9.2527
路易斯安那州:新奥尔良 29.9511 0.9511
缅因州:波特兰 45.5051 16.5051
马里兰州:巴尔的摩 39.2904 10.2904
马萨诸塞州:波士顿 42.3601 13.3601
密歇根州:底特律 42.3314 13.3314
明尼苏达州:明尼阿波利斯 44.9778 15.9778
密西西比州:杰克逊 32.3547 3.3547
密苏里州:堪萨斯城 39.0997 10.0997
蒙大拿州:比林斯 45.7833 16.7833
内布拉斯加州:奥马哈 41.2565 12.2565
内华达州:拉斯维加斯 36.1699 7.1699
新罕布什尔州:曼彻斯特 42.9956 13.9956
新泽西州:纽瓦克 40.7357 11.7357
新墨西哥:阿尔伯克基 35.0844 6.0844
纽约:纽约市 40.7128 11.7128
北卡罗来纳州:夏洛特 35.2271 6.2271
北达科他州:法戈 46.8772 17.8772
俄亥俄州:哥伦布 39.9612 10.9612
俄克拉荷马州:俄克拉荷马城 35.4676 6.4676
俄勒冈州:波特兰 45.5051 16.5051
宾夕法尼亚州:费城 39.9526 10.9526
罗德岛:普罗维登斯 41.824 12.824
南卡罗来纳州:查尔斯顿 32.7765 3.7765
南达科他州:苏福尔斯 43.5473 14.5473
田纳西州:纳什维尔 36.1627 7.1627
德克萨斯州:休斯顿 29.7604 0.7604
犹他州:盐湖城 40.7608 11.7608
佛蒙特州:伯灵顿 44.4759 15.4759
弗吉尼亚州:弗吉尼亚海滩 36.8529 7.8529
华盛顿:西雅图 47.6062 18.6062
西弗吉尼亚州:查尔斯顿 38.3498 9.3498
威斯康星州:密尔沃基 43.0389 14.0389
怀俄明州:夏安 41.14 12.14
华盛顿特区 38.9072 9.9072
AE,如果它能让您在 Excel 中更轻松,请发送电子邮件至 [电子邮件保护] 我会用电子表格回复。 接下来我也会根据冬天的温度和湿度给你状态; res的好建议!
我认为国家与气候和冠状病毒的相关性将更加重要,因为各国的气候变化要大得多。
以下是按冬季平均温度划分的州。
The key is 0-10 = 1;10-15=2; 15-20=3; 20-25=4; 25-30=5; 30-35=6; 35-40=7; 40-45=8; 45-50=9; 50-55=10; 55-60=11; 60-65=12
基于
https://www.currentresults.com/Weather/US/average-state-temperatures-in-winter.php
州/最大城市冬季气温 (1-12)
阿拉巴马州 9
阿拉斯加 1
亚利桑那州 8
阿肯色州 8
加利福尼亚州 9
科罗拉多 5
康涅狄格 5
特拉华州 7
佛罗里达州 11
格鲁吉亚 9
夏威夷 12
爱达荷州 5
伊利诺伊州 5
印第安纳州 5
爱荷华州 4
堪萨斯 6
肯塔基 7
路易斯安那州 10
缅因州 3
马里兰 6
马萨诸塞州 5
密歇根 4
明尼苏达 2
密西西比州 9
密苏里州 6
蒙大拿 4
内布拉斯加州 5
内华达州 6
新罕布什尔州 4
新泽西州 6
新墨西哥 7
纽约 4
北卡罗来纳 8
北达科他州 2
俄亥俄州 5
俄克拉荷马 7
俄勒冈 6
宾夕法尼亚州 5
罗德岛 5
南卡罗来纳州 9
南达科他州 3
田纳西州 7
德州 9
犹他州 5
佛蒙特州 3
弗吉尼亚州 7
华盛顿 6
西弗吉尼亚州 6
威斯康星州 3
怀俄明州 4
华盛顿特区 5
平均露点怎么样。 这是各州的数据。
https://www.forbes.com/sites/brianbrettschneider/2018/08/23/oh-the-humidity-why-is-alaska-the-most-humid-state/
查看 XNUMX 月、XNUMX 月和 XNUMX 月的平均露点可能会更好,但该数据更难收集。
或者温度。 这是平均气温和冬季平均气温。
https://www.currentresults.com/Weather/US/average-annual-state-temperatures.php
https://www.currentresults.com/Weather/US/average-state-temperatures-in-winter.php
或降水。
https://www.currentresults.com/Weather/US/average-annual-state-precipitation.php
同样,季节性可能会更好。
另一方面,人格特质如何? 这篇论文的最后一页有一个按州划分的 5 大表格。 将这些用于其他目的也可能很有趣。
https://www.apa.org/news/press/releases/2013/10/regions-personalities
https://www.apa.org/pubs/journals/releases/psp-a0034434.pdf
作为二进制变量的就地避难所顺序和初始/最强顺序的日期似乎可能是有用的变量。
PS您(AE)是否尝试过任何多元回归? 看到种族(4 个类别变量)、肥胖、密度、露点和外向性之类的东西会很有趣。 然后进行一些分析以了解它们如何协同工作(ANOVA?)。
PPS 同意状态相当不精确。 好像大城市会好点。 特别是因为现在他们似乎正在推动传播。
回复:@ res,@ Audacious Epigone
由于露点相对于特定湿度是非线性的(并且 R0 相对于特定湿度是非线性的,我认为这会放大问题),因此尝试对露点进行一些变换可能是有意义的。 上个月此评论中的一些相关图形。
https://www.unz.com/anepigone/covid-19s-hard-fail/#comment-3764901
r^2= 80 年每位饮酒者饮酒的 1994%
这些是与约 19 个生态变量相关的 COVID-500 死亡人数,按其决定系数 (r^2) 排序. 电子表格位于 这个链接给有兴趣的人. 请注意,如果我有更多时间,我会删除绝对计数的行(即:不是人均)。 对于那些对“VerbalChange1991to2001”的含义感兴趣的人:这是 SAT 语言成绩的变化。
谢谢! 考虑到它仅适用于 11 个州,顶部的酒精变量就不那么令人印象深刻了。
但是有很多变量的 r^2 大约为 50% 或更高。 我惊呆了
犹太人/意大利人/多米尼加人/俄罗斯人/波多黎各人/牙买加人在所有 50 个州的相关性都非常好。 堕胎是另一个有趣的变量,但只有 44 个州的数据。
我不明白的是,那些在 AE 的数据中没有更强烈地显示出来。 AE 看到相关性 (r!) 小于 0.2! 我本来希望克林顿和人口密度能够很好地代表上述人口变量。
AE,你能看出这与你的结果有什么关系吗? 他是否使用了类似的死亡数据? 您可以尝试将您的数据集与他的数据集合并或在此处发布您的数据吗?
PS DanHessinMD,您是否打算将数据滚动到该电子表格中? 或者如果你和AE不这样做,我应该这样做吗?
回复:@Audacious Epigone
我已经清理了各州的相关性,以消除误导性的酒精数据(N=11 且远非正态分布)以及基本上增加混乱的绝对计数变量。
这种数据搜索是简化形式建模正确受到攻击的关键原因。 它的 ”计算机科学” 统计 - 易于实施,但完全不了解结果的基本统计特性。
如果你做 500 个初步的成对 ρᵢⱼ ,一个 束 其中的显着性是偶然的 - 由于因变量被截断,显着性 ρᵢⱼ 的比例将大于 αN (其中 α 是显着性水平, N 是样本量)。
ρᵢⱼ 是 Pharma- 和 Psych-'quant' 的“首选”机制 [原文] - 这就是为什么他们的“研究”不能复制的原因。
回到我教书的时候 应用计量经济学模型 (本科三年级科目),第一次作业的 3% 用于检查孩子们是否正确理解诸如 虚假相关,并向他们展示为什么数据搜索与现在所谓的 对黑客 (我们当时称其为“数据疏浚”:这两个词都不够贬义——应该这样称呼它:“腐败的量化“)。
也许班上 10% 的人真的“明白”了这个概念——这些孩子必须在 HS 孩子的第 95 个百分位(进入第一年),这门课是选修课,需要 3 分的“学分”前导科目:统计(第一年); 计量经济学理论(第 1 年); 应用计量经济学(第 2 年)。 (NB...“学分”:该范围内的三年级,但仍然是美国的“A”)。
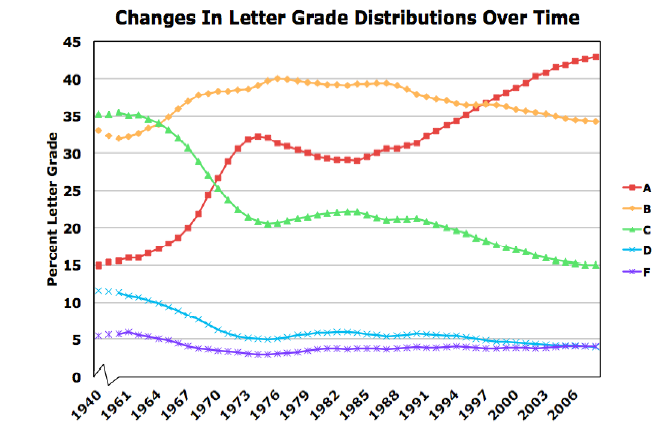
美式“A”开始于中位数之上(下图为 2016 年):在 4 年制大学中 所有成绩的 42%. 所以 '学霸'实际上已经变得毫无意义——它几乎不意味着'比平均水平更好'.
https://www.timeshighereducation.com/sites/default/files/grades2.png
相比之下,在我 母校,在前 3 年获得平均学分的学生有资格参加荣誉学年 - 但如果他们只是勉强进入然后尝试荣誉学业,他们将在最后的五分之一中完成。 在本科阶段,只有前十分位数的学生获得了 D一门学科成绩优异,只有班上前 1-5 名的学生获得 HIGH Distinction:“高清平均值”几乎是闻所未闻的。
可惜蒙纳士 BEc 孩子的平均成绩为“D”:在经济学排名世界前几十名的大学中,学生人数占学生人数的前百分之几(24 年排名第 2013;现在排名第 39)。 . 获得“D”平均值. 一定是高等教育史上最被误解的群体。
(我认为蒙纳士现在已经转向 GPA,以迎合 HR-tard 的愚蠢。想象一下一些愚蠢的 HR-tard 在成绩单上看到一堆“D”级)。
回复:@James Bowery
公共交通使用情况如何? 快速浏览一下这里的图表看起来令人鼓舞:
https://en.m.wikipedia.org/wiki/List_of_U.S._cities_with_high_transit_ridership
确实,这里看起来确实有很大的潜力。 美国大约有 300 个城市的人口在 100 万以上。 这是为将来添加的书签,谢谢。
与总人口数据没有任何关联。 没有任何。
原因是因为病毒不会像每个人都假设的那样随机传播。 相反,以下过程中的每一步都遵循帕累托分布。
1. 暴露:你暴露了吗?
2. 如果您被暴露,您是否感染了病毒?
3. 如果你感染了,你有没有产生抗体?
4. 如果您产生了抗体,您有没有出现任何症状?
5. 如果您出现症状,是否严重到需要就医?
6.你死了吗?
当你在第 6 位死去的时候,你看到的是那些几乎正朝着一个充满命运的约会而奔跑的人,而不是那些由其他变量的横截面代表的人。 这就像通过测量看台上人们的生命体征来询问谁将赢得田径比赛。
而另一面—— 好厄运[1] 模型 - 假设看台上的人可以与赛道上的人运行相同的平均时间。
[1] 曼弗雷德·奥术 前几天在评论中使用了“OK Doomer”; 这比“四眼天鸡".
在技术上和精神上都严重和严重错误。
精神上:
当流行病学“当局”利用其庞大的资源进行 FA 时,人们歇斯底里地四处奔波,在这种情况下,由资源有限(时间、金钱、教育和数据访问)的人来做他们所能做的最好的事情. 这意味着那些有资源的人应该进行探索性数据分析,这是人们可能会合理地羞辱当局做他们的工作的唯一方法。 批评有关努力的细节,是的。 这符合形势的精神。
技术上:
你所说的“总人口数据”是“生态数据”。 虽然挑剔者将试图通过批评“生态谬误”(至少比 Stat 101“相关性并不意味着因果关系!”)来得分,但生态相关性是流行病学追溯到其起源的基础。 例如,如果没有水井和暴发的生态相关性,就无法检测到霍乱是水传播的。 看到人们在没有检验任何假设的情况下简单地查看数据就“浪费原始数据”可能会激怒学究们的羽毛,但是当涉及到公共卫生时,我们正在处理生态关系,所以 TS 有时这些关系是显而易见的,就像人口密度一样,人们可能会试图通过说找到这样的相关性作为对探索性数据分析的一般批评的理由是没有信息的,从而摆脱了迂腐的分数。 但这仅仅是确认偏差,它忽略了一种可能性 - 非常明显 - 一个所谓的“虚假”相关性可能会在其中包含一个线索,指向一个以前未被注意到的潜在变量,它可能会拯救生命。
大胆的追随者——
在这里做了一些数据处理。
诚然,全州与死亡率和纬度的相关性很弱。
但资本纬度与每百万死亡率之间的国家相关性是 ***难以置信的强大***.
我在 x 轴上绘制了国家首都的纬度,在 y 轴上绘制了每百万冠状病毒死亡人数的图。 相关性非常强。
我将自己限制在进行了大量测试的国家——大约 140 个国家。
有零个国家的首都位于北纬 30 度以南,每百万人中的死亡人数超过 20。 有 25 个国家的首都位于北纬 30 度以北,每百万死亡人数超过 20。 美国现在每百万人中有 65 人死亡。 在赤道以南,零国家的死亡人数超过每百万人 7 人。
100 个国家/地区死于冠状病毒的人数超过每百万人 40 人,其中每个国家的首都都在北纬 XNUMX 度以北。
DC位于纬度39,纽约位于纬度41。 新冠病毒与气候有着非常强烈的相关性,但美国只是没有给出足够的变化来正确显示这一点。 整个美国基本上在 30 到 45 之间,因此气候的相关性远没有全球范围内的那么强。
让它顺其自然。 它不会消失。 培养群体免疫。 我试图告诉你你只是在恐慌,“请帮助我政府!” 乐队马车。 政府征服现在感觉如何?
这些是与约 19 个生态变量相关的 COVID-500 死亡人数,按其决定系数 (r^2) 排序. 电子表格位于 这个链接给有兴趣的人. 请注意,如果我有更多时间,我会删除绝对计数的行(即:不是人均)。 对于那些对“VerbalChange1991to2001”的含义感兴趣的人:这是 SAT 语言成绩的变化。
回复:@res、@James Bowery、@Kratoklastes
谢谢! 考虑到它仅适用于 11 个州,顶部的酒精变量就不那么令人印象深刻了。
但是有很多变量的 r^2 大约为 50% 或更高。 我惊呆了
犹太人/意大利人/多米尼加人/俄罗斯人/波多黎各人/牙买加人在所有 50 个州的相关性都非常好。 堕胎是另一个有趣的变量,但只有 44 个州的数据。
我不明白的是,那些在 AE 的数据中没有更强烈地显示出来。 AE 看到相关性 (r!) 小于 0.2! 我本来希望克林顿和人口密度能够很好地代表上述人口变量。
AE,你能看出这与你的结果有什么关系吗? 他是否使用了类似的死亡数据? 您可以尝试将您的数据集与他的数据集合并或在此处发布您的数据吗?
PS DanHessinMD,您是否打算将数据滚动到该电子表格中? 或者如果你和AE不这样做,我应该这样做吗?
我用了 Worldometers 的每百万人死亡人数.
这是一个很好的主题。 TL;DR:无论模型说什么,病毒都会继续传播,直到数十万甚至几百万美国人死亡。 作者研究了潜在的经济影响,并得出结论,最好在短期内牺牲部分经济,而不是让人们集体死亡,这将对经济增长造成永久性损害。 然而,我并不完全同意。 该分析没有考虑西方移民政策。
冠状病毒:它甚至可以被阻止吗?
以下是美国统治阶级下一步可能会做的事情(我的看法):
他们将通过撤回用于测试中心的联邦资金和通过故意曲解科学数据来欺负媒体的方式巧妙地减少测试和报告。
他们已经在做前者。
然后,他们将使用当前的模型(考虑到社会疏远/封锁)来宣布战胜病毒; 达到这种模式的顶峰将等同于击败它,证明恢复正常业务是合理的。 他们还会说,该模型预测的流感死亡人数仅略高于年度报告的流感死亡人数,并斥责以前的批评者为“歇斯底里”,甚至可能是阴谋论者,以阻止未来对该主题的任何报道,因为当病毒不可避免地在第二波浪潮中卷土重来时(至少在选举之后,大部分情况下都不会被报道)。
他们会让病毒在没有免疫力的人群中燃烧。 最终结果将比该模型当前预测的死亡人数(约 82 人死亡)多得多,因为它假设我们在很长一段时间内使 R0 在全球范围内低于约 1。 从长远来看,很可能无法在美国遏制该病毒,因为它是如此广泛和具有传染性。 只需要少数感染者就可以确保人口最终被感染。 即使美国在国内控制住了它,只允许少数受感染的外来者进入也将重新启动这一过程。 它需要一些时间才能在第三世界中燃烧,它应该作为病毒库至少几个月。
与此同时,在“持不同政见者”权利上为唐纳德特朗普寻找许多被买断的水运船,以充当受控反对派。 They'll deny there's a problem in video after YouTube video – all in the faint hope Donald Trump will get reelected. 他不会。 YouTube 还将继续允许像 David Icke 这样的边缘阴谋论者发表胡说八道,说他们一开始甚至不是病毒——只是 5G 的副作用或其他什么。 他们会容忍这些人,因为他们的言辞服务于淡化病毒的更大目的。
几年后,有人会进行一项研究,发现美国死于 Covid-19 的人数比最初报告的要多得多,可能是 8 或 9(或更高)的倍数。 但这一切都被方便地扫到了地毯下,所以很少有人会听到。
之后,寻找 Covid-19 大赦后的推动以及“基于技能的”移民的增加。 WaPo 已经在他们对遇险的所谓“梦想家”的报道中暗示了这一点。 基本上,他们会让很多土生土长的美国人死去,然后很快用外国工人代替他们。 毕竟,“美国的生意就是生意”。 “演出必须继续。” 哦,唐纳德·特朗普将在 2020 年大选中落败,因为他的部分基地已经消失; 共和党在未来也不会具有竞争力,因为前者的基地被绝大多数投票支持民主的移民所取代。
“持不同政见者”权利也将名誉扫地,因为他们歇斯底里地拥抱经济/自由,而不是保护同胞的生命,同时淡化病毒——在声称是对人民福祉感兴趣的民族活动家之后(这是显而易见的现在欺诈)。 暴露为骗子、华尔街崇拜者和未受过教育的边缘阴谋论者,他们将随着唐纳德特朗普的选举失利而逐渐消失。 他们已经在用 Qanon 推动它。 但这对大多数人来说可能是越界了。 基本上,任何聪明的人都会在之后远离这群人,至少在一些新人物出现并用一种不受这种胡说八道的新哲学重新命名之前。 Deep State 赢得了 4D 国际象棋比赛——目前。
旁注:有问题的 YouTuber 已从谷歌搜索结果中除名,尽管他是非暴力的。 原因:他们不喜欢他对女权主义之类的看法。 请记住,下次像 Samantha Bee 这样的人声称保守派没有受到审查。 她是对的。 每个人都在被审查。 这家伙是一个进步的无神论者。 我猜他们正试图让他的 R0 低于 1,逻辑是如果他们禁止他的视频出现在搜索中,他的基础将慢慢消失,因为他无法获得新的订阅者。 然后他们可以通过声称他们实际上没有禁止任何人来转移批评。 考虑到这种情况,有一些讽刺意味。
这些是与约 19 个生态变量相关的 COVID-500 死亡人数,按其决定系数 (r^2) 排序. 电子表格位于 这个链接给有兴趣的人. 请注意,如果我有更多时间,我会删除绝对计数的行(即:不是人均)。 对于那些对“VerbalChange1991to2001”的含义感兴趣的人:这是 SAT 语言成绩的变化。
回复:@res、@James Bowery、@Kratoklastes
我已经清理了各州的相关性,以消除误导性的酒精数据(N=11 且远非正态分布)以及基本上增加混乱的绝对计数变量。
如果您查看我更新的博客文章,您会注意到顶部有很强的城市相关性:
变量 rr^2 N
移民多米尼加共和国人均1998 83.13% 69.10% 51
HIVPositiveTestsPercapita2001 77.75% 60.45% 33
犹太人人均 1999 年 75.56% 57.09% 51
West_IndianPercapita1990 72.36% 52.35% 51
意大利人PercentOfWhites 70.20% 49.28% 51
俄罗斯人均 1990 年 69.29% 48.01% 51
然而,这很有趣,相比之下,InnerCityPercapita1990 相差甚远:
InnerCityPercapita1990 42.16% 17.77% 51
还要注意 ImmigrantsChina1998 比较低:
移民中国1998 43.83% 19.21% 51
如果有人想弄乱县级相关性, 这是我的 LaboratoryOfTheCounties CSV.
以下是县案例.
以下是县死亡人数.
这些是与约 19 个生态变量相关的 COVID-500 死亡人数,按其决定系数 (r^2) 排序. 电子表格位于 这个链接给有兴趣的人. 请注意,如果我有更多时间,我会删除绝对计数的行(即:不是人均)。 对于那些对“VerbalChange1991to2001”的含义感兴趣的人:这是 SAT 语言成绩的变化。
回复:@res、@James Bowery、@Kratoklastes
这种数据搜索是简化形式建模正确受到攻击的关键原因。 它的 ”计算机科学” 统计 - 易于实施,但完全不了解结果的基本统计特性。
如果你做 500 个初步的成对 ρᵢⱼ ,一个 束 其中的显着性是偶然的——由于因变量被截断,显着性 ρᵢⱼ 的比例将大于 αN (其中 α 是显着性水平, N 是样本量)。
ρᵢⱼ 是 Pharma- 和 Psych-'quant' 的“首选”机制 [原文]——这就是为什么他们的“研究”不能复制的原因。
回到我教书的时候 应用计量经济学模型 (本科三年级科目),第一次作业的 3% 用于检查孩子们是否正确理解诸如 虚假相关,并向他们展示为什么数据搜索与现在所谓的 对黑客 (我们当时称其为“数据挖掘”:这两个词都不够贬义——应该这样称呼它:“腐败的量化“)。
也许班上 10% 的人真的“明白”了这个概念——这些孩子必须在 HS 孩子的第 95 个百分位(才能进入第一年),而且这门课是选修课,需要 3 年级的“学分”前导科目:统计(第一年); 计量经济学理论(第 1 年); 应用计量经济学(第 2 年)。 (NB…“学分”:该范围内的三年级,但仍然是美国的“A”)。
美式“A”开始于中位数之上(下图为 2016 年):在 4 年制大学中 所有成绩的 42%. 所以 '学霸'实际上已经变得毫无意义——它几乎不意味着'比平均水平更好“。
相比之下,在我 母校,在前 3 年获得平均学分的学生有资格获得荣誉学年 - 但如果他们只是勉强进入然后尝试荣誉学业,他们将在最后的五分之一中完成。 在本科阶段,只有前十分位数的学生获得了 D一门学科成绩优异,只有班上前 1-5 名的学生获得 HIGH D异想天开:“高清平均值”几乎是闻所未闻的。
可惜蒙纳士 BEc 孩子的平均成绩为“D”:在一所大学的学生群体中排名前百分之几(24 年排名第 2013;现在排名第 39)…… 获得“D”平均值. 一定是高等教育史上最被误解的群体。
(我认为蒙纳士现在已经转向 GPA,以迎合 HR-tard 的愚蠢。想象一下一些愚蠢的 HR-tard 在成绩单上看到一堆“D”级)。
听说过“探索性数据分析“?我的博文原标题是”各州 COVID-19 死亡人数的探索性数据分析“有充分的理由。
如果您想在上述 EDA 的过早“发布”时与我争吵,您就赢了。 如果你想在因果推理上与我争论不休,你最好把你的游戏提高一个标准差左右。
听说过算法信息论吗?
回复:@Kratoklastes
原因是因为病毒不会像每个人都假设的那样随机传播。 相反,以下过程中的每一步都遵循帕累托分布。
1. 暴露:你暴露了吗?
2. 如果您被暴露,您是否感染了病毒?
3. 如果你感染了,你有没有产生抗体?
4. 如果您产生了抗体,您有没有出现任何症状?
5. 如果您出现症状,是否严重到需要就医?
6.你死了吗?
当你在第 6 位死去的时候,你看到的是那些几乎正朝着一个充满命运的约会而奔跑的人,而不是那些由其他变量的横截面代表的人。 这就像通过测量看台上人们的生命体征来询问谁将赢得田径比赛。
回复:@Kratoklastes,@James Bowery
放得很漂亮。
而另一方面—— 好厄运[1] 模型——假设看台上的人可以与赛道上的人跑相同的平均时间。
[1] 曼弗雷德·奥术 前几天在评论中使用了“OK Doomer”; 它比“四眼天鸡“。
这种数据搜索是简化形式建模正确受到攻击的关键原因。 它的 ”计算机科学” 统计 - 易于实施,但完全不了解结果的基本统计特性。
如果你做 500 个初步的成对 ρᵢⱼ ,一个 束 其中的显着性是偶然的 - 由于因变量被截断,显着性 ρᵢⱼ 的比例将大于 αN (其中 α 是显着性水平, N 是样本量)。
ρᵢⱼ 是 Pharma- 和 Psych-'quant' 的“首选”机制 [原文] - 这就是为什么他们的“研究”不能复制的原因。
回到我教书的时候 应用计量经济学模型 (本科三年级科目),第一次作业的 3% 用于检查孩子们是否正确理解诸如 虚假相关,并向他们展示为什么数据搜索与现在所谓的 对黑客 (我们当时称其为“数据疏浚”:这两个词都不够贬义——应该这样称呼它:“腐败的量化“)。
也许班上 10% 的人真的“明白”了这个概念——这些孩子必须在 HS 孩子的第 95 个百分位(进入第一年),这门课是选修课,需要 3 分的“学分”前导科目:统计(第一年); 计量经济学理论(第 1 年); 应用计量经济学(第 2 年)。 (NB...“学分”:该范围内的三年级,但仍然是美国的“A”)。
美式“A”开始于中位数之上(下图为 2016 年):在 4 年制大学中 所有成绩的 42%. 所以 '学霸'实际上已经变得毫无意义——它几乎不意味着'比平均水平更好'.
https://www.timeshighereducation.com/sites/default/files/grades2.png
相比之下,在我 母校,在前 3 年获得平均学分的学生有资格参加荣誉学年 - 但如果他们只是勉强进入然后尝试荣誉学业,他们将在最后的五分之一中完成。 在本科阶段,只有前十分位数的学生获得了 D一门学科成绩优异,只有班上前 1-5 名的学生获得 HIGH Distinction:“高清平均值”几乎是闻所未闻的。
可惜蒙纳士 BEc 孩子的平均成绩为“D”:在经济学排名世界前几十名的大学中,学生人数占学生人数的前百分之几(24 年排名第 2013;现在排名第 39)。 . 获得“D”平均值. 一定是高等教育史上最被误解的群体。
(我认为蒙纳士现在已经转向 GPA,以迎合 HR-tard 的愚蠢。想象一下一些愚蠢的 HR-tard 在成绩单上看到一堆“D”级)。
回复:@James Bowery
听说过“探索性数据分析“? 我的博文原标题是“各州 COVID-19 死亡人数的探索性数据分析” 有充分的理由。
如果您想在上述 EDA 的过早“发布”时与我争吵,您就赢了。 如果你想在因果推理上与我争论不休,你最好把你的游戏提高一个标准差左右。
听说过算法信息论吗?
通过试图将 EDA 与数据挖掘混为一谈来歪曲 EDA,这对你没有任何帮助。
EDA 主要是关于在预先指定的模型中深入了解每个系列的特征 -
• 描述性统计数据(例如,均值;方差;偏斜;分位数);
• 单位根和平稳性检验(即常数均值;有限方差);
• 分布统计(基于描述的分布选择)。
EDA 是构建模型的正常部分 - 特定 某些变量集与其他变量集之间的某种假设的行为或理论关系。
相比之下,数据挖掘是“我有这个东西,还有一大堆其他东西的数据。 其中一些其他事情可能是 [心]与我感兴趣的变量有关...”
那不是 EDA:它是“CompSci”(又名“你好,世界") "寻找模型“。 它的 ”吮吸它,看看“,并且应该被认为是顽皮的——或者至少,受到 邦费罗尼校正 (即,要求假设在 α/M 意义,在哪里 M 是执行的单个成对 ρᵢⱼ 的数量)。
Tukey(字面上是在 EDA 上“写书”)是关于 了解您的数据,而不仅仅是把厨房水槽扔在一个问题上,看看什么粘住了,把最粘的外生变量称为“解释性”。
最近有很多人认为 EDA 是复制危机的根本根源(尤其是在 Psych 和 Pharma 中):使用理论关联作为关于深层因果关系的主张的基础是一个众所周知的问题。
量化经济学已经有 2 代人无法摆脱这种事情了——但它在其他地方仍然无处不在…… 它需要在火灾中死去.
Lucas (1976) 正确地指出 简化形式的证据从根本上是薄弱的,并且是从行为/结构模型中寻求“深层”参数的不良替代品。
这是计量经济学家和经济建模师在 1976 年就已经知道的事情(Ramsay 对模型规范的 RESET 测试于 1968 年发布;Chow 的测试于 1960 年发布,并在 60 年代中期用于测试参数稳定性)……但是卢卡斯对经济学来说是一个更广泛的“启示”。
绝对正确的是,到 70 年代中期,经济学中出现了大量的、糟糕的、简化形式的量化(包括但不限于菲利普斯曲线和奥肯定律)。
其中很多是由 quant-dilettantes - 挥手的论文作者完成的,他们明白这门学科有点迷恋 quant,并且不再对挥手很感兴趣。 肯定知道更好的人玩世不恭地做了很多事情。
Quant 是一种轻松发表论文的方法——因此在相当著名的经济学期刊(尤其是 AER)上发表了大量论文,人们应用了简化形式的 OLS(但没有达到在第二年计量经济学科目通过的标准) )。
早在此之前 - 在卢卡斯写下这个“洞察力”之前的五年,在凯德兰和普雷斯科特假装之前 其 想法很新颖——Leontief 和他在哈佛大学的研究生在推广投入产出模型以开发基于深层结构基础的动态、政策不变模型方面取得了长足的进步。
Leontief 的一位学生(Dixon - 我的博士生导师)在 1972 年的博士论文中明确了对底层结构的要求(联合最大化理论, 发表在阿姆斯特丹北荷兰"对经济分析的贡献”系列在 1975 年)。
正如卢卡斯所写的同一年,两名对我的训练非常有影响力的人(上述的迪克森和艾伦鲍威尔)提议(与文森特一起) 一个 CRESH/CRETH 生产结构 这是 非常具体 追求“深层”行为的结果。
[1] CRE[S|T]H:[替代|变换]弹性的常数比,类比
回复:@James Bowery
原因是因为病毒不会像每个人都假设的那样随机传播。 相反,以下过程中的每一步都遵循帕累托分布。
1. 暴露:你暴露了吗?
2. 如果您被暴露,您是否感染了病毒?
3. 如果你感染了,你有没有产生抗体?
4. 如果您产生了抗体,您有没有出现任何症状?
5. 如果您出现症状,是否严重到需要就医?
6.你死了吗?
当你在第 6 位死去的时候,你看到的是那些几乎正朝着一个充满命运的约会而奔跑的人,而不是那些由其他变量的横截面代表的人。 这就像通过测量看台上人们的生命体征来询问谁将赢得田径比赛。
回复:@Kratoklastes,@James Bowery
在技术上和精神上都严重和严重错误。
精神上:
当流行病学“当局”利用其巨大的资源进行 FA 时,人们歇斯底里地四处奔波,在这种情况下,资源(时间、金钱、教育和数据访问)有限的人必须尽其所能. 这意味着那些有资源的人应该进行探索性数据分析,这是人们可能会合理地羞辱当局做他们的工作的唯一方法。 批评有关努力的细节,是的。 这符合形势的精神。
技术上:
你所说的“总人口数据”是“生态数据”。 虽然挑剔者将试图通过批评“生态谬误”(这至少比 Stat 101“相关性并不意味着因果关系!”)来得分,但生态相关性是流行病学追溯到其起源的基础。 例如,如果没有水井和暴发的生态相关性,就无法检测到霍乱是水传播的。 看到人们在没有检验任何假设的情况下简单地查看它,这可能会激怒书呆子的羽毛,但是当涉及到公共卫生时,我们正在处理生态关系,所以 TS 有时这些关系是显而易见的,就像人口密度一样,人们可能会试图通过说找到这样的相关性来证明对探索性数据分析的一般批评是无意义的,从而摆脱迂腐的分数。 但这只是确认偏差,它忽略了一种可能性——非常明显——一个所谓的“虚假”相关性可能会在其中包含一个线索,指向一个以前未被注意到的潜在变量,它可能会拯救生命。
回复:@Kratoklastes
真正难以做到的事情之一是住院、严重程度和死亡率数据中绝对明显的年龄组划分。
似乎各个年龄段(例如非常年轻的人)的感染率(非常)大致保持不变——尽管必须记住,要计入 I 你必须经过测试,这在美国是一个非常有偏见的样本。
这就像在 SEIR 模型中还有另外两个隔间:
从 'Infected' 到 ' 的额外转换概率被感染,症状严重到足以产生 T是',其中一些子集需要 H精神化,其中一些 D即。
不过,这并不意味着 Pr(I|E) 在各个年龄段都是恒定的:相对更强壮的 20-29 岁的人在给定的暴露水平下感染的机会可能较低。
20-29 岁人群的超额感染率(在澳大利亚的数据中占其人口份额的 150%)可能表明这些人的社交互动最多——他们的大部分社交互动将在群体内进行。
相反,平均 70 岁以上的病人——迄今为止,死亡人数最多的人——与 covid19 的社会接触范围要窄得多(而且变化较少):在正常的事件过程中,它是家庭或疗养院的工作人员——如果一名工作人员无症状,他们可能会感染疗养院的数十名囚犯。
对不同年龄组的转换概率进行建模是一项挑战,因为每个年龄组的联系人的年龄分布将不同——70 多个年龄组中的 I、T、H 和 D 中的数字可能来自从 20-29yo 的接触中暴露(反之亦然)。
冠状病毒:它甚至可以被阻止吗?
https://www.youtube.com/watch?v=0ERi2cL730o
以下是美国统治阶级下一步可能会做的事情(我的看法):
他们将通过撤回用于测试中心的联邦资金和通过故意曲解科学数据来欺负媒体的方式巧妙地减少测试和报告。
他们已经在做前者。然后,他们将使用当前的模型(考虑到社会疏远/封锁)来宣布战胜病毒; 达到这种模式的顶峰将等同于击败它,证明恢复正常业务是合理的。 他们还会说,该模型预测的流感死亡人数仅略高于年度报告的流感死亡人数,并斥责先前的批评者为“歇斯底里”,甚至可能是阴谋论者,以阻止未来在该病毒不可避免地在第二波浪潮中卷土重来时对该主题的任何报道(至少在选举之后,大部分情况下都不会被报道)。
他们会让病毒在没有免疫力的人群中燃烧。 最终结果将比该模型当前预测的死亡人数(约 82 人死亡)多得多,因为它假设我们在很长一段时间内使 R0 在全球范围内低于约 1。 从长远来看,很可能无法在美国遏制该病毒,因为它是如此广泛和具有传染性。 只需要少数感染者就可以确保人口最终被感染。 即使美国在国内控制住了它,只允许少数受感染的外来者进入也将重新启动这一过程。 它需要一些时间才能在第三世界中燃烧,它应该作为病毒库至少几个月。
与此同时,在“持不同政见者”权利上为唐纳德特朗普寻找许多被买断的水运船,以充当受控反对派。 They'll deny there's a problem in video after YouTube video – all in the faint hope Donald Trump will get reelected. 他不会。 YouTube 还将继续允许像 David Icke 这样的边缘阴谋论者发表关于他们甚至不是病毒的胡说八道——只是 5G 的副作用或其他什么。 他们会容忍这些人,因为他们的言辞服务于淡化病毒的更大目的。
几年后,有人会进行一项研究,发现美国死于 Covid-19 的人数比最初报告的要多得多,可能是 8 或 9(或更高)的倍数。 但这一切都被方便地扫到了地毯下,所以很少有人会听到。
之后,寻找 Covid-19 大赦后的推动以及“基于技能的”移民的增加。 WaPo已经通过他们对遇险的所谓“梦想家”的报道暗示了这一点。 基本上,他们会让很多土生土长的美国人死去,然后很快用外国工人代替他们。 毕竟,“美国的生意就是生意”。 “演出必须继续。” 哦,唐纳德·特朗普将在 2020 年大选中落败,因为他的部分基地已经消失; 共和党在未来也不会具有竞争力,因为前者的基地被绝大多数投票支持民主的移民所取代。
“持不同政见者”权利也将名誉扫地,因为他们歇斯底里地拥抱经济/自由,而不是保护同胞的生命,同时淡化病毒——在声称自己是对人民福祉感兴趣的民族活动家之后(这是一个现在明显的欺诈行为)。 暴露为骗子、华尔街崇拜者和未受过教育的边缘阴谋论者,他们将随着唐纳德特朗普的选举失利而逐渐消失。 他们已经在用 Qanon 推动它。 但这对大多数人来说可能是越界了。 基本上,任何聪明的人都会在之后远离这群人,至少在一些新人物出现并用一种不受这种胡说八道的新哲学重新命名之前。 Deep State 赢得了 4D 国际象棋比赛——目前。
旁注:有问题的 YouTuber 已从谷歌搜索结果中除名,尽管他是非暴力的。 原因:他们不喜欢他对女权主义之类的看法。 请记住,下次像 Samantha Bee 这样的人声称保守派没有受到审查。 她是对的。 每个人都在被审查。 这家伙是一个进步的无神论者。 我猜他们正试图让他的 R0 低于 1,逻辑是如果他们禁止他的视频出现在搜索中,他的基础将慢慢消失,因为他无法获得新的订阅者。 然后他们可以通过声称他们实际上没有禁止任何人来转移批评。 考虑到这种情况,有一些讽刺意味。
回复:@Divine Right
这可能也是没有进行全面经济停摆的更强有力的原因之一。 通过低估病毒,最小化者创造了一种情况,当他们真正应该说的是如下内容时,他们得到了与他们想要的相反的情况:“因为我们没有免疫力,而且因为这种新病毒的传染性很强,所以我们永远无法完全控制它——直到我们有疫苗,这可能需要 12 到 18 个月的时间。 在那之前我们不能关闭东西,所以我们别无选择。 也许我们可以随着病毒的传播分阶段进行有限的关闭,但我们不能一次关闭所有东西,因为它无论如何都没有任何好处。 它仍然会传播,即使我们在这里消灭它,它仍然会在第三世界徘徊,而一旦有一个外部感染者进来,我们可能只有一两个月的时间,整个国家都会感染它。” 我认为这会比很多人最终做的事情要好得多——告诉他们的 Twitter 追随者嘲笑戴面罩的人或试图声称这只是流感或阴谋。 政府没有足够的个人防护装备也使人们非常害怕,并使情况变得更糟。
意大利受灾最严重的城镇之一对每个人进行了测试:没有发现很多抗体携带者。 所以你的快乐场景看起来并不好。
关注 Chris Martenson 的视频帖子。 他对这个问题很关注。
顺便说一句,关于疫苗有一些坏消息:在对抗再次感染方面,电晕抗体非常弱。 所以这种病毒更像是艾滋病毒——不是一个很好的疫苗目标。
我也是 Martenson 的忠实粉丝——链接在这里:
https://www.youtube.com/channel/UCD2-QVBQi48RRQTD4Jhxu8w
他预测了短缺、恐慌和封锁——早在有人关注简历之前,就让我在“安静的时间”做好了准备。
这并不能保证他对病毒的其余分析是准确的——但我相信他胜过无数没有三个月准确简历预测记录的互联网发帖者。
关注 Chris Martenson 的视频帖子。 他对这个问题很关注。
顺便说一句,关于疫苗有一些坏消息:在对抗再次感染方面,电晕抗体非常弱。 所以这种病毒更像是艾滋病毒——不是一个很好的疫苗目标。
回复:@Justvisiting
我也是马滕森的忠实粉丝——链接在这里:
https://www.youtube.com/channel/UCD2-QVBQi48RRQTD4Jhxu8w
他预测了短缺、恐慌和封锁——早在有人关注简历之前,就让我在“安静的时间”做好了准备。
这并不能保证他对病毒的其余分析是准确的——但我比无数没有三个月准确简历预测记录的互联网发帖者更信任他。
听说过“探索性数据分析“?我的博文原标题是”各州 COVID-19 死亡人数的探索性数据分析“有充分的理由。
如果您想在上述 EDA 的过早“发布”时与我争吵,您就赢了。 如果你想在因果推理上与我争论不休,你最好把你的游戏提高一个标准差左右。
听说过算法信息论吗?
回复:@Kratoklastes
通过试图将 EDA 与数据挖掘混为一谈来歪曲 EDA,这对你没有任何帮助。
EDA 主要是关于在预先指定的模型中深入了解每个系列的特征——
• 描述性统计数据(例如,均值;方差;偏斜;分位数);
• 单位根和平稳性检验(即常数均值;有限方差);
• 分布统计(基于描述的分布选择)。
EDA 是构建模型的正常部分—— 特定 某些变量集与其他变量集之间的某种假设的行为或理论关系。
相比之下,数据挖掘是“我有这个东西,还有一大堆其他东西的数据。 其中一些其他事情可能是 [心]与我感兴趣的变量有关......“
那不是 EDA:它是“CompSci”(又名“你好,世界“)”寻找模型“。 它的 ”吮吸它,看看“,并且应该被认为是淘气的——或者至少,受到 邦费罗尼校正 (即,要求假设在 α/M 意义,在哪里 M 是执行的单个成对 ρᵢⱼ 的数量)。
Tukey(字面上是在 EDA 上“写书”的人)是关于 了解您的数据,而不仅仅是把厨房水槽扔在一个问题上,看看什么粘住了,把最粘的外生变量称为“解释性”。
最近有很多人认为 EDA 是复制危机的根本根源(尤其是在 Psych 和 Pharma 中):使用理论关联作为关于深层因果关系的主张的基础是一个众所周知的问题。
量化经济学已经有 2 代人无法摆脱这种事情了——但它在其他地方仍然无处不在…… 它需要在火灾中死去.
Lucas (1976) 正确地指出 简化形式的证据从根本上是薄弱的,并且是从行为/结构模型中寻求“深层”参数的不良替代品。
这是计量经济学家和经济建模师在 1976 年就已经知道的事情(Ramsay 的模型规范 RESET 测试于 1968 年发布;Chow 的测试于 1960 年发布,并在 60 年代中期用于测试参数稳定性)……但卢卡斯是对经济学更广泛的“启示”。
绝对正确的是,到 70 年代中期,经济学中出现了大量的、糟糕的、简化形式的量化(包括但不限于菲利普斯曲线和奥肯定律)。
很多都是由 quant 爱好者完成的——挥手的文章作者知道这门学科对 quant 有点迷恋,对挥手不再感兴趣。 肯定知道更好的人玩世不恭地做了很多事情。
Quant 是一种轻松发表论文的方法——因此在相当著名的经济学期刊(尤其是 AER)上发表了大量论文,人们在其中应用了简化形式的 OLS(但没有达到在第二年计量经济学科目通过的标准) )。
早在此之前——在卢卡斯写下这个“洞察力”之前的五年,在基德兰和普雷斯科特假装之前 其 想法很新颖——Leontief 和他在哈佛大学的研究生在推广投入产出模型以开发基于深层结构基础的动态、政策不变模型方面取得了长足的进步。
Leontief 的一位学生(Dixon——我的博士生导师)在 1972 年的博士论文中明确了对底层结构的要求(联合最大化理论,发表于阿姆斯特丹北荷兰“对经济分析的贡献”系列在 1975 年)。
卢卡斯写到的同一年,对我的训练有很大影响的两个人(前面提到的迪克森和艾伦鲍威尔)提议(和文森特一起) 一个 CRESH/CRETH 生产结构 这是 非常具体 追求“深层”行为的结果。
[1] CRE[S|T]H:[替代|变换]弹性的常数比,类比
EDA 主要是关于深入了解每个系列的特征 预先指定的模型
不,这不对。 虽然 EDA 可以在一类模型的上下文中完成(实际上,非正式地,否则不可能这样做,因为我们都有非正式的先验),但并不限于这种情况。
Tukey(字面上是在 EDA 上“写书”的人)是关于 了解您的数据
哦,好悲伤。 停止尝试获得迂腐分数。 John Tukey 是我的同事* Charles Sinclair Smith 的导师,后者后来在 Carter 的领导下共同创立了能源信息管理局,并负责建立初始数据分析程序。 然后他去指导系统开发基金会,在那里他资助了神经网络 PDP 书籍、Hinton 和 Werbos 等,从而结束了第一个神经网络冬天。 我非常清楚“顽皮” EDA 的局限性。 如果您想提供帮助,请查看我的电子表格并提供一些额外的 EDA。
您可以从 Bonferroni 校正开始,因为您提出了这一点。
*查理和我回到了 90 年代中期,但最近(2007 年)我搬到了爱荷华州农村的下一个县,他从那里半退休,我们就因果推理进行了长达十年的来回。 这是偶然的,因为在 2006 年,我说服 Marcus Hutter 为最近再次出现在新闻中的数据无损压缩奖提供资金。 我当时的立场是,并且今天仍然是,数据的无损压缩为模型选择产生了最佳信息标准,并且包括因果模型。 我终于让查理同意我的观点。 你的整个“统计”世界都被像我这样的人颠覆了,你把我当作孩子一样对待。 把它剪下来,把自己应用到手头的问题上。
https://nypost.com/2020/04/12/the-coronavirus-can-travel-at-least-13-feet-new-study-shows/
其他州几乎关闭了一切,但上个月,每个人都在杂货店排队等候,彼此相距六英尺,这样他们就可以得到食物而不会饿死。 这种类型的关闭可能不像以前想象的那么有效,因此我们可能已经破坏了经济,在阻止疾病传播方面取得的成果比我们想象的要少。
回复:@Brian Reilly
马克,13 英尺? 不是27? 不是 14 或 12 英尺? 6英尺安全吗? 里面还是外面? 有风还是无风? 是否像篝火冒出的烟雾一样悬挂在空气中(静止的空气?完全静止??)?
我打电话给BS。 它是各种流感。 杀死一些人。 BFD。 可能会杀了我,我想。 每个人都死于某种东西。 我从没想过管理这个国家的白痴会关闭它,因为如果我死了,他们就给了它,我现在不这么认为。 这是一个骗局,被用来压制人们并实现接管,否则对于工作它的精神病患者来说,这将不是那么容易。
通过试图将 EDA 与数据挖掘混为一谈来歪曲 EDA,这对你没有任何帮助。
EDA 主要是关于在预先指定的模型中深入了解每个系列的特征 -
• 描述性统计数据(例如,均值;方差;偏斜;分位数);
• 单位根和平稳性检验(即常数均值;有限方差);
• 分布统计(基于描述的分布选择)。
EDA 是构建模型的正常部分 - 特定 某些变量集与其他变量集之间的某种假设的行为或理论关系。
相比之下,数据挖掘是“我有这个东西,还有一大堆其他东西的数据。 其中一些其他事情可能是 [心]与我感兴趣的变量有关...”
那不是 EDA:它是“CompSci”(又名“你好,世界") "寻找模型“。 它的 ”吮吸它,看看“,并且应该被认为是顽皮的——或者至少,受到 邦费罗尼校正 (即,要求假设在 α/M 意义,在哪里 M 是执行的单个成对 ρᵢⱼ 的数量)。
Tukey(字面上是在 EDA 上“写书”)是关于 了解您的数据,而不仅仅是把厨房水槽扔在一个问题上,看看什么粘住了,把最粘的外生变量称为“解释性”。
最近有很多人认为 EDA 是复制危机的根本根源(尤其是在 Psych 和 Pharma 中):使用理论关联作为关于深层因果关系的主张的基础是一个众所周知的问题。
量化经济学已经有 2 代人无法摆脱这种事情了——但它在其他地方仍然无处不在…… 它需要在火灾中死去.
Lucas (1976) 正确地指出 简化形式的证据从根本上是薄弱的,并且是从行为/结构模型中寻求“深层”参数的不良替代品。
这是计量经济学家和经济建模师在 1976 年就已经知道的事情(Ramsay 对模型规范的 RESET 测试于 1968 年发布;Chow 的测试于 1960 年发布,并在 60 年代中期用于测试参数稳定性)……但是卢卡斯对经济学来说是一个更广泛的“启示”。
绝对正确的是,到 70 年代中期,经济学中出现了大量的、糟糕的、简化形式的量化(包括但不限于菲利普斯曲线和奥肯定律)。
其中很多是由 quant-dilettantes - 挥手的论文作者完成的,他们明白这门学科有点迷恋 quant,并且不再对挥手很感兴趣。 肯定知道更好的人玩世不恭地做了很多事情。
Quant 是一种轻松发表论文的方法——因此在相当著名的经济学期刊(尤其是 AER)上发表了大量论文,人们应用了简化形式的 OLS(但没有达到在第二年计量经济学科目通过的标准) )。
早在此之前 - 在卢卡斯写下这个“洞察力”之前的五年,在凯德兰和普雷斯科特假装之前 其 想法很新颖——Leontief 和他在哈佛大学的研究生在推广投入产出模型以开发基于深层结构基础的动态、政策不变模型方面取得了长足的进步。
Leontief 的一位学生(Dixon - 我的博士生导师)在 1972 年的博士论文中明确了对底层结构的要求(联合最大化理论, 发表在阿姆斯特丹北荷兰"对经济分析的贡献”系列在 1975 年)。
正如卢卡斯所写的同一年,两名对我的训练非常有影响力的人(上述的迪克森和艾伦鲍威尔)提议(与文森特一起) 一个 CRESH/CRETH 生产结构 这是 非常具体 追求“深层”行为的结果。
[1] CRE[S|T]H:[替代|变换]弹性的常数比,类比
回复:@James Bowery
EDA 主要是关于深入了解每个系列的特征 预先指定的模型
不,这不对。 虽然 EDA 可以在一类模型的上下文中完成(实际上,非正式地,否则不可能这样做,因为我们都有非正式的先验),但并不限于这种情况。
Tukey(字面上是在 EDA 上“写书”的人)是关于 了解您的数据
哦,好悲伤。 停止尝试获得迂腐分数。 John Tukey 是我的同事* Charles Sinclair Smith 的导师,后者后来在 Carter 的领导下共同创立了能源信息管理局,并负责建立初始数据分析程序。 然后他去指导系统开发基金会,在那里他资助了神经网络 PDP 书籍、Hinton 和 Werbos 等,从而结束了第一个神经网络冬天。 我非常清楚“顽皮”EDA 的局限性。 如果您想提供帮助,请查看我的电子表格并提供一些额外的 EDA。
您可以从 Bonferroni 校正开始,因为您提出了这一点。
*查理和我回到了 90 年代中期,但最近(2007 年)我搬到了爱荷华州农村的下一个县,他从那里半退休,我们就因果推理进行了长达十年的来回。 这是偶然的,因为在 2006 年,我说服 Marcus Hutter 为最近再次出现在新闻中的数据无损压缩奖提供资金。 我当时的立场是,并且今天仍然是,数据的无损压缩为模型选择产生了最佳信息标准,并且包括因果模型。 我终于让查理同意我的观点。 你的整个“统计”世界都被像我这样的人颠覆了,你把我当作孩子一样对待。 把它剪下来,把自己应用到手头的问题上。
至于因果推理,我建议你熟悉一下 Hector Zenil 最近发表在 Nature 上的工作:
“算法生成模型的因果反卷积“。
也许 这个小视频 将帮助您了解这种处理大数据的方法与“统计”之间的区别,但这不是我会制作的视频,因为它没有描述与统计方法的关系。
无损压缩消除“虚假相关”的方式与路径分析的方式没有什么不同:当可以通过消除相应路径而不增加整体误差来降低图形复杂性时,就会暴露虚假相关性。 理解 AIT 方法的关键是理解误差单位与模型复杂性单位的维度相同:比特,或者更具体地说,比特构成了生成被建模数据的算法。
在这个阶段可能只是噪音太大了。 太多的混乱信号无法显示。 也许如果疾病进展更接近饱和。
我同意 Hess 博士的观点,并期望最终会显示出纬度(维生素 D),尤其是那些具有非洲血统的人。
认识到统计学上的幼稚应该保持这些相关性的观点,我已经更新了介绍 桌子:
顺便说一句,AE,这种不愉快涉及到我一直在告诉你(和其他数学家)关于无损压缩的内容。 如果现实主义右翼没有开始真正将无损压缩作为统一社会模型的选择标准,那么它将错失摆脱“社会科学”话语的修辞污水的绝好机会,很可能错失阻止三十年战争。
你们需要多长时间才能解决这个问题,这样我们才能对社会伪科学进行核打击?
我承认,看到黑人和棕色暴徒的军队遇到一生都在射击的好男孩,看看他们以多快的速度被击溃,这将是一件很有趣的事情。天纪律在火中溶解。 不知道我能看到多少,但出来的视频会很疯狂。
回复:@James Bowery
关于生态相关性统计显着性意义的问题。
当我们查看 50 个状态时,N = 50(如果包括 DC,则为 51)。 在线计算器给出 28 作为 Pearson r 在 05 水平(对于 N = 50 和 N = 51)的显着性的最小值,我仍然记得大约十年前我在州级相关性方面所做的一些工作.
当时,我记得在某处读到显着性水平不适用于这种情况,因为它们与从样本到总体的推论有关。 然而,在这种情况下没有这样的推论,因为样本 *是* 人口。
另一种解释是存在这样的推论,这些州是来自假设人口的样本,因此显着性水平是相关的。
这两种解释中的哪一种更符合统计学上的精明?
你们需要多长时间才能解决这个问题,这样我们才能对社会伪科学进行核打击?
回复:@先生。 合理的
我们已经过去了。 与社会结果最紧密的关联是种族(如果他再次出现在 SBPDL,请询问帕特博伊尔),任何使用种族作为预测指标的行为在 1970 年代都是一种诅咒。 由于(((他们)))已禁止,因此不会就该主题进行思想会议。
我承认,看到黑人和棕色暴徒的军队遇到一生都在射击的好男孩,看看他们以多快的速度被击溃,这将是一件很有趣的事情。天纪律在火中溶解。 不知道我能看到多少,但出来的视频会很疯狂。
话语战争的前线不是那些继续吹嘘诡辩的人,而是这些诡辩者的学生——他们越来越了解机器学习的原理,并且由于提供的薪水而越来越有动力去纠正它. 虽然大量“愚蠢的钱”确实从寻求网络效应的垄断企业中流出,从而在该领域产生 120 分贝的噪音,但有足够多的钱将用于支持敏锐的头脑——只是通过机会。 这就是 DotCon 时代的愚蠢资金暴风雪所发生的事情。 其中一部分落到了贝索斯和马斯克这样的人手中 我的联盟在 1991 年通过的法律.
仅此而已,因为在震耳欲聋的信噪比咆哮中,信号的每一次增加都相当于对噪音的大幅抑制。
回复:@先生。 合理的
我承认,看到黑人和棕色暴徒的军队遇到一生都在射击的好男孩,看看他们以多快的速度被击溃,这将是一件很有趣的事情。天纪律在火中溶解。 不知道我能看到多少,但出来的视频会很疯狂。
回复:@James Bowery
话语战的前线不是那些继续吹嘘诡辩的人,而是这些诡辩家的学生——这些学生越来越了解机器学习的原理,并且由于提供的薪水而越来越有动力去纠正它。 虽然大量“愚蠢的钱”确实从寻求网络效应的垄断企业中流出,从而在该领域产生 120dB 的噪音,但有足够多的资金用于支持敏锐的头脑——只是偶然. 这就是 DotCon 时代的愚蠢资金暴风雪所发生的事情。 其中一部分落到了贝索斯和马斯克这样的人手中 我的联盟在 1991 年通过的法律.
仅此而已,因为在震耳欲聋的信噪比咆哮中,信号的每一次增加都相当于对噪音的大幅抑制。
回复:@James Bowery
这里有很多东西可以咀嚼。 我将在本周末投入必要的时间来解决它。
话语战争的前线不是那些继续吹嘘诡辩的人,而是这些诡辩者的学生——他们越来越了解机器学习的原理,并且由于提供的薪水而越来越有动力去纠正它. 虽然大量“愚蠢的钱”确实从寻求网络效应的垄断企业中流出,从而在该领域产生 120 分贝的噪音,但有足够多的钱将用于支持敏锐的头脑——只是通过机会。 这就是 DotCon 时代的愚蠢资金暴风雪所发生的事情。 其中一部分落到了贝索斯和马斯克这样的人手中 我的联盟在 1991 年通过的法律.
仅此而已,因为在震耳欲聋的信噪比咆哮中,信号的每一次增加都相当于对噪音的大幅抑制。
回复:@先生。 合理的
一旦他们敢说非 PC 的话,或者发布“种族主义”产品,他们就会像 James Damore 一样迅速被取消。
如果有的话,神童不必说什么 奖金附加于对各种纵向社会措施的无损压缩的渐进式改进. 他们只会提交更好的统一社会模型,并享有银行存款和模型的吹牛权利。 财富 500 强认为警方将不得不通过使用与现实相对应的模型来挖掘代码以找出违规员工“被骗”。 在大多数情况下,那些认为警察太愚蠢而不能这样做的人——但其他渴望证明自己的印章的孩子会足够聪明。 是的,当然,其中一些会 在 关于一些谷歌神童过去用来更好地塑造社会的东西,但在审讯期间,员工只能使用一些口齿不清的种族否认主义言论,比如:“哦,当然,我只是暴露了一个潜在变量,一些无牙的雅虎认为这就是所谓的民俗学”种族'。但我们未来的所有人都与 Ingosc 合作!”
冠状病毒是一种呼吸道疾病。 较冷的温度会使病毒传播得更快。 我们正在经历一个相当寒冷的四月,所以这些数字还没有达到峰值。 随着温度的升高,太阳将有助于提高影响免疫系统的维生素 D 水平。 服用维生素 C 和 D 是帮助免疫系统的好主意。 让它们进入食物比药片更好。
无论数据集如何,试图在这里找到一个神奇的相关性都是不可能的。 这是一种新疾病,预后的所有参数仍然大多未知。 他们说它来自蝙蝠,所以蝙蝠的环境可能也是一个需要考虑的因素。
回复:@James Bowery
如果有的话,神童不必说什么 奖金附加于对各种纵向社会措施的无损压缩的渐进式改进. 他们只会提交更好的统一社会模型,并享有银行存款和模型的吹牛权利。 财富 500 强认为,警方将不得不通过使用与现实相对应的模型来挖掘代码以找出违规员工“被骗”。 在大多数情况下,那些认为警察太愚蠢而不能这样做的人——但其他渴望证明自己能力的孩子会足够聪明。 是的,当然,其中一些会 在 关于一些谷歌神童过去用来更好地塑造社会的东西,但在审讯期间,员工可以只使用一些口齿不清的种族否认主义言论,比如:“哦,当然,我只是暴露了一个潜在变量,一些无牙的雅虎人认为这就是所谓的民俗学”种族'。 但我们的未来都与 Ingosc 合作!”
平均露点怎么样。 这是各州的数据。
https://www.forbes.com/sites/brianbrettschneider/2018/08/23/oh-the-humidity-why-is-alaska-the-most-humid-state/
查看 XNUMX 月、XNUMX 月和 XNUMX 月的平均露点可能会更好,但该数据更难收集。
或者温度。 这是平均气温和冬季平均气温。
https://www.currentresults.com/Weather/US/average-annual-state-temperatures.php
https://www.currentresults.com/Weather/US/average-state-temperatures-in-winter.php
或降水。
https://www.currentresults.com/Weather/US/average-annual-state-precipitation.php
同样,季节性可能会更好。
另一方面,人格特质如何? 这篇论文的最后一页有一个按州划分的 5 大表格。 将这些用于其他目的也可能很有趣。
https://www.apa.org/news/press/releases/2013/10/regions-personalities
https://www.apa.org/pubs/journals/releases/psp-a0034434.pdf
作为二进制变量的就地避难所顺序和初始/最强顺序的日期似乎可能是有用的变量。
PS您(AE)是否尝试过任何多元回归? 看到种族(4 个类别变量)、肥胖、密度、露点和外向性之类的东西会很有趣。 然后进行一些分析以了解它们如何协同工作(ANOVA?)。
PPS 同意状态相当不精确。 好像大城市会好点。 特别是因为现在他们似乎正在推动传播。
回复:@ res,@ Audacious Epigone
我没有。 我用于多变量分析的工具包目前不起作用。 如果尘埃落定之前还没有解决,我会再买一个,但我会等到那时再发布其他任何东西。 感觉这可能比在这一点上澄清数字更令人困惑,因为数字像它们一样跳来跳去。
https://en.m.wikipedia.org/wiki/List_of_U.S._cities_with_high_transit_ridership
回复:@Audacious Epigone
确实,这里看起来确实有很大的潜力。 美国大约有 300 个城市的人口在 100 万以上。 这是为将来添加的书签,谢谢。
谢谢! 考虑到它仅适用于 11 个州,顶部的酒精变量就不那么令人印象深刻了。
但是有很多变量的 r^2 大约为 50% 或更高。 我惊呆了
犹太人/意大利人/多米尼加人/俄罗斯人/波多黎各人/牙买加人在所有 50 个州的相关性都非常好。 堕胎是另一个有趣的变量,但只有 44 个州的数据。
我不明白的是,那些在 AE 的数据中没有更强烈地显示出来。 AE 看到相关性 (r!) 小于 0.2! 我本来希望克林顿和人口密度能够很好地代表上述人口变量。
AE,你能看出这与你的结果有什么关系吗? 他是否使用了类似的死亡数据? 您可以尝试将您的数据集与他的数据集合并或在此处发布您的数据吗?
PS DanHessinMD,您是否打算将数据滚动到该电子表格中? 或者如果你和AE不这样做,我应该这样做吗?
回复:@Audacious Epigone
我用了 Worldometers 的每百万人死亡人数.